2017年6月,Google Brain(现在已和Deep Mind合并)的Illia Polosukhin、Ashish Vaswani 等八位作者,发表了论文《Attention Is All You Need》,正式提出Transformer架构。
彼时,这篇论文被归类为机器翻译领域的一次技术迭代,没人意识到它是人工智能历史上的万历十五年。
一、Transformer为了解决什么问题
在这篇论文之前,统治机器学习界的是RNN(循环神经网络)及其变体LSTM(长短期记忆网络)。而RNN最显著的特征是线性、串行。通过时间步长的引入,RNN在生成下一个token时,可以把前序所有时间步长的信息装进隐藏状态里带过来,因此理论上RNN可以把任意长度的序列作为输入项。
但实际情况并不理想。
RNN在处理长序列时,需要将信息通过时间步逐层传递。由于反向传播涉及权重矩阵的连乘,如果激活函数的导数小于1,梯度会随着时间步的增加呈指数级衰减(梯度消失);如果权重矩阵较大,梯度会呈指数级增长,导致模型训练极度不稳定,甚至直接报错(梯度爆炸)。所以实际上RNN只能记住10-20步的信息。
就像当你读一本长篇小说,读到第500页时,你已经忽略了第1页埋下的伏笔。RNN也是如此,随着序列的不断拉长,早期的信息在传递过程中会逐渐衰减,直至消失,这种情况下RNN在用最近的短期记忆去覆盖长期的文本信息,自然不准确。
除此之外,RNN也无法并行计算。它的核心逻辑是下一个步长的计算依赖于这一步长的结果。模型必须先算出第1个词,才能算第2个词,以此类推。串行计算模式导致它无法充分利用GPU等加速硬件的并行计算能力,训练效率极低。
Transformer架构就是为了解决以上问题被提出的。
二、Transformer是怎么工作的
在开始之前,我们阅览2个概念,有助于我们进一步理解Transformer的底层原理:
大模型:生成式大模型本体很像一个由多个经过训练后生成的、复杂且高维矩阵组合在一起的动态概率字典。一般的大模型(如Llama 3或 GPT-3)包含的权重矩阵数量通常在几百个数量级。其中包括全局矩阵和每一层的矩阵:
- 全局矩阵一般只有2个:词嵌入矩阵(We,斜体的大写字母代表它是一个矩阵,下同)和输出头矩阵(Whead );
- 每一层的矩阵:自注意力机制每一层都存在4个权重矩阵(WQ、WK、WV、WO),前馈神经网络每一层需要3个,分别用来做门控、升维、降维(Transformer论文中只使用ReLU、FNN 2个矩阵)。
模型的训练:在所有的模型矩阵里填入随机数,开始往前逐层输入(前向传播,Forward Pass)。随即开始复盘,根据已有的答案(事先准备好的),告诉模型猜错了,猜错的离谱程度用交叉熵损失函数大小来表示,Loss=-log(预测正确字的概率)。然后开始反过来找错误的症结在哪(反向传播,Backpropagation),具体操作就是计算出参数W对最终 Loss 的影响力,即梯度=∂Loss/∂W。再通过优化器尝试更新矩阵参数(Wnew =Wold – 学习率×梯度)。随着梯度下降,结果会逐渐收敛。
以下进入正文:
Transformer依然沿用了RNN编码器-解码器(Encoder-Decoder)这部分结构,但是摒弃了传统的循环和卷积,完全依赖注意力机制(Attention)来捕捉输入和输出之间的全局依赖关系。我们将根据论文里的流程图,从Inputs开始,依照逻辑顺序来解释Transformer的具体工作流程:
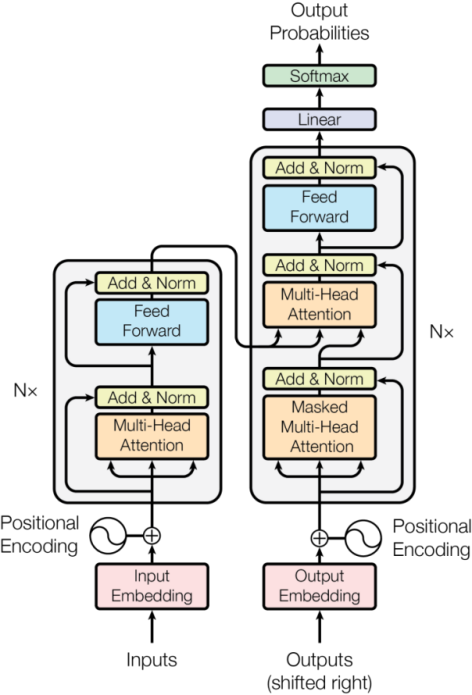
Transformer架构示意
第一阶段:预处理
(1)词嵌入(Input Embedding)
词嵌入表可以采用Word2Vec、Glove等算法预训练得到,也可以在 Transformer 中训练得到。查询词嵌入表,把包含n个单词(字)的Inputs序列转换成一个固定的向量X=[w1,w2,…,wn],其维度为 n×d model (论文里模型维度d model =512),X的每一行都代表一个词。这一步是为了把序列变成能用计算机计算的形式。基于这种变换,后续训练过程可以进行大量并行的矩阵运算,可被并行计算硬件加速。
计算过程:
- 输入为X=[w1,w2,…,wn]
- 初始化一个词嵌入矩阵,V为词表大小
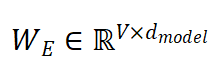
- 对于每个Wi,从WE中取出对应的第i行向量
- 通过词嵌入矩阵变换后,X=Xembed
(2)位置编码(Positional Encoding)
因为Transformer内部没有RNN结构,它并行处理所有词,如果不加位置编码,模型无法理解语序。所以在预处理时,需要加入每个词的位置信息。具体操作上,Transformer会将一整句话中每个词的位置信息通过正弦或余弦函数编码成与X维度一致的向量,直接加到Xembed中。这样变换以后,每个词都带有了其他词的位置信息。
计算过程:
- 使用正弦和余弦函数生成位置矩阵PE:
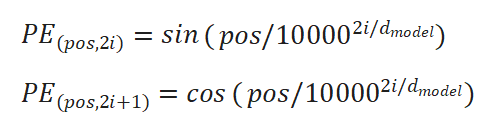
- 相加:Xinput=Xembed+PE
第二阶段:编码器(The Encoder)
Nx框内部的编码器流程会重复x次,以下是单次的处理流程:
(3)多头自注意力机制(Multi-Head Self-Attention)
这是Transformer的核心机制。
Xinput 分别与三个权重矩阵WQ、WK、WV 相乘,得到Q、K、V矩阵。Q与KT相乘,得到注意力权重矩阵Score,矩阵中的每一个数字代表了两个词之间的相关性。计算序列中每一个词之间的关联度,可以解决一词多义问题。如bank代表银行还是河岸,取决于它和周围哪个词在数学意义上关联更紧密。
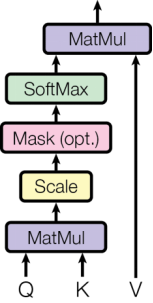
缩放点积注意力Scaled Dot-Product Attention
多头(Multi-Head)就是让Q、K、V矩阵,乘以不同的权重矩阵W,通过线性变换后,再运行单个的注意力运算,最后将多个头产生的结果进行拼接融合。其意义在于,不同的权重矩阵W可以对应语法的不同方面,比如一个头关注语义指代,一个头关注动宾语法等。举个例子,在处理”The animal didn’t cross the street because it was too tired”这句话时,自注意力机制会让”it” 这个词与 “animal”产生极高的关联度,从而“理解”it指的是动物而不是街道。论文里是8头,意味着它会生成8组不同的Q、K、V 矩阵。
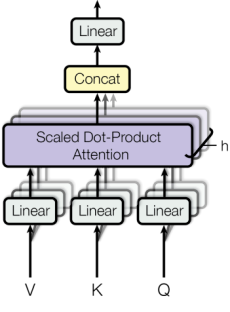
多头注意力Multi-Head Attention
以论文的8头为例,具体计算过程:
- 线性变换:对于8个头中的每一个头i(i=1,2,…,8),都有对应的权重矩阵WiQ、WiK、WiV,维度为dmodel×dk(其中dk=dmodel/8),将Xinput分别乘以三个权重矩阵:
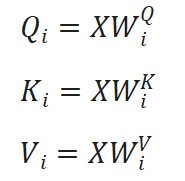
- 计算单个头的注意力权重矩阵:Score=Qi · KiT
- 对注意力权重进行缩放,防止点积过大导致Softmax进入饱和区,使得梯度趋近于0
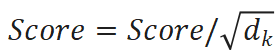
- 转化为概率分布(每一行之和都为1):Attention_Weights=Softmax(Score)。第i行、j列的数字大小表示了第i个词和第j个词的关联度
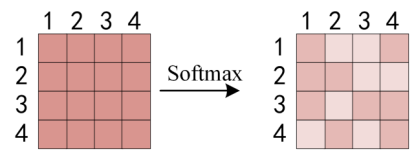
- 加权求和,用权重矩阵乘Vi:Headi=Attention_Weights · Vi
- 拼接与融合:将8个头的输出拼接,再经过一个权重矩阵WO融合:
MultiHead=Concat(Head1,…,Head8)
Xoutput=MultiHead · Wo
以上计算过程可以综合为一个Transformer经典公式:
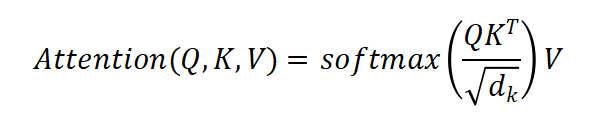
(4)残差连接与归一化(Add & Norm)
在传统的RNN里,梯度在层层传递中会逐渐丢失。Add就是为了解决梯度消失的问题。具体是怎么做到的?假设在Add机制引入之前,Attention的输出是MultiHeadAttention(X)(简称M(X));Add机制的加入,会将Attention的输入X和输出M(X)相加,然后标准化。如果在这一层没学到什么有用的东西,M(X)趋近于0,那么原始输入X依然能毫发无损地传到下一层,在训练回传误差梯度时,Add也可以确保梯度可以直接跳回前面的层,解决了梯度消失的问题。
再说Norm。在模型内部,每一个神经元输出的绝对值可能会有天壤之别,有的特别大,有的特别小。这种波动会让下一层的学习变得非常吃力:注意力机制天然会让模型更关注大的数值,忽略小的数值,或者某一个神经元的数字逐渐大到计算机算不出来。Norm就是对这些数字做一些整理。将神经元的数值重置,使其整体的均值为0、方差为1,但是保留了所有神经元之间的区别特征,保证信息无损。Norm可以让模型不需要因为输入数据的剧烈波动而反复调整,训练速度更快。
(5)前馈神经网络(Feed-Forward Networks,FNN)
FNN是人工神经网络中最基础、也是最早期的架构,本质上是一个多层函数嵌套在一起构成的模型,输入的数据会逐层映射,最终输出。理论上只要有足够的隐藏层和节点,FNN可以拟合任何复杂的线性或非线性函数关系,但它不考虑上下文数据的关联。
做个不那么恰当但是可以帮助理解的比喻:FNN像一个硬盘,负责存储模型在训练数据中学到的静态事实;Attention则像一个CPU,负责处理当前的动态上下文,把相关的词拉到一起。没有Attention,模型无法理解上下文;没有FNN,模型缺乏足够的非线性变换能力来处理复杂的文本特征。
具体计算过程:
- 多层线性变换+1个ReLU激活函数:FFN(x)=max(0,xW1+b1)W2+b2
- lFNN之后会再重复做一次Add & Norm
以上步骤重复X次,编码器会输出一个包含深度上下文信息的矩阵。这组矩阵将作为Key和Value传给Decoder使用。
第三阶段:解码器(The Decoder)
这一部分只做简单说明。
首先是已准备好的Outputs被预处理,预处理的方式与Encoder阶段类似。处理完后,把它喂给Decoder。开始以下步骤:
(6)掩码多头注意力机制(Masked Multi-Head Attention)
和Encoder的多头自注意力机制类似,不同的是但加了一个Mask(掩码)。当模型在预测第i个词时,它不能看到第i+n个词,防止反向传播失效。
(7)交叉注意力机制(Encoder-Decoder Attention)
与Encoder阶段的多头自注意力机制类似,这里也有Q、K、V矩阵,但它们的来源不同。以翻译工作为例:Q来自Decoder上一层的输出,是已经完成翻译后的句子序列,也就是喂给模型的答案;K和V来自Encoder的最终输出,是翻译前的原始句子序列。然后运行比较独特的交叉注意力机制:Decoder用它的Q去扫描Encoder的K,找到匹配度最高的部分,取出对应的V。
通过这个过程,Decoder得到了一个融合了源句相关信息的向量。具体计算过程:
- 先经过各自的线性层进行特征转换:
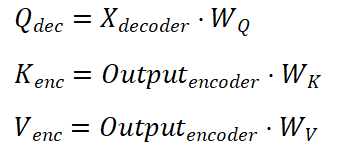
- 计算单个头的注意力权重矩阵:Score=Qi · KiT
- 归一化:
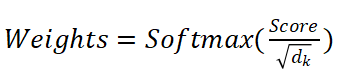
- 加权求和:
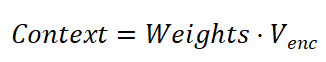
(8)重复 FNN 和 Add & Norm
第四阶段:输出生成(Final Output)
(9)线性层 (Linear)
把Decoder 最终输出的向量(dmodel维度)投影到一个巨大的词表维度,将抽象的语义向量转化为对具体单词的打分。
具体计算过程:
- Logits=Outputdecoder · Wvocab(Wvocab形状为dmodel ×V)
(10)Softmax层
把上面的数值转化成概率分布。概率最高的那个词,就是模型预测的下一个词。
- 输出一个概率分布,总和为1
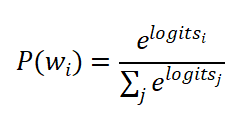
以上,就是通过Transformer做一次前向传播的完整过程。
三、关于Transformer的延伸思考
RNN像是我们大多数时候的线性思维习惯,简单直接,而且有迹可循。我们在时间的线性流淌中,基于昨天的经验、信息和知识,来推导今日。再基于今日发生的事、对过往正确信息的验真(奖励)以及对过往错误信息的勘误(反向传播),来不断强化正确的认知或修正错误的认知,以此来推测明日的可能性,并不断提升其准确率。
这种线性思维带来了很多好处,且被验证过:
- 物种的延续:早期的人类,在缺乏参考资料的情况下,只需要记住进食某种食物的伙伴状态不好,后续就会降低食用的概率。基于过去的负面经验来预测危险,是物种延续的一项重要法则。
- 建立安全感:基于熵增,一个孤立系统总是趋向于从有序走向无序,世界也是一样。线性思维通过经验为我们临时建立了一种可以预测的秩序感。如果我们不能确信:太阳明天会像昨天一样升起、我能用昨天赚来的钱保证我今天可以一日三餐,那感觉会很惶恐。
基于线性思维,我们天然只关注与自己相似的信息,而不是所有有用的信息。这在社会学上被称为同质性偏好。但如果人类社会失去了对其他序列和生命体的包容机制,就会退化为一个个互不理解的孤岛。
Transformer其实包含了一种隐喻,个体、社会如果可以对接触到的所有信息进行全面的、带权重的注意力分配,再结合内部消化处理(FNN),积累到一定参数规模时,可能新的文明形式将会涌现。
再说回到大模型目前面临的黑箱问题。
虽然大模型的隐藏层无法被符号主义解释,其生成能力目前还是隐性且概率柔性,但我认为它在一定程度上也和人类的学习模式已经有相似性,人类大脑何尝不是一种运行机制最复杂的黑箱?在传统的知识传递范式中,我们的知识结构搭建在很多基础公理上,即使你对世界和事物的诞生、演化、迭代的最底层逻辑并不完全清晰,但你仍能根据已经被普遍认可的公理,甚至是凭借数次试错建立的直觉,结合已经被证实正确事物的强化,就可以得出结论,而且这个结论最终也符合我们见证到的表观结果。